He hecho dos programitas que sacan las relaciones de amistad en en el interior de dos comunidades virtuales, barrapunto y menéame. Después he sacado imágenes gráficas de dichas relaciones, para visualizar, en lo posible, la compleja estructura de esas "relaciones sociales". Aunque el análisis de los datos no es muy riguroso, el resultado puede interesar tanto a los que les gusta el análisis de redes sociales online como a los que les gusta la ver programitas de ejemplo. En este caso están hechos en Erlang, y están acompañados de algún enlace que he ido recopilando en el camino.
La red social de barrapunto
Me gusta mucho ver gráficos relacionados con las ciencias que tratan de estudiar la complejidad, como los de visual complexity*, no porque sepa mucho de ello, sino como mero aficionado. El caso es que llamó mucho la atención también la representación visual de la red social de feevy (comentado por gente que sabe de esto, de entre los cuales me excluyo, en Un mar de flores).
(*Otra actualización:Parece que alguien envió esta entrada a visualcomplexity y ha sido aceptada: Social Network of barrapunto. Gracias al anónimo submitter que lo envió. Me siento muy halagado ;) )
Pues bien, el otro día se me ocurrió que se podría hacer lo mismo con los usuarios de barrapunto, que en el fondo no deja de ser una red con unas relaciones muy bien definidas: la relación de amistad y enemistad. Y también se me ocurrió que lo podría hacer con un programita que capturara esas relaciones y las dejara en formato DOT. Para ello he usado Erlang. ¿Por qué? Pues porque si. Se podía haber hecho con wget o curl y awk, y/o perl o ... Pero bueno, me apetecía hacer algo más que un Hola mundo! en este lenguaje. Y, a decir verdad, me lo he pasado muy bien programando en él y descubriéndolo.
Comentaba Alex que para visualizar la redes sociales solían usar SocNetV, pero que en este caso usó Graphviz Ambos admiten para modelar las redes el lenguaje de definición DOT. Son los programas que yo he usado para los gráficos que viene a continuación.
Primero la imagen tal cual, sin ordenar demasiado, con socnetv:

Intentando desenredar la red, estos programas tienen criterios para representar la información en función de una serie de parámetros que suelen calcularse en función del las distintas definiciones de centralidad...
Pegaré aquí las imágenes que creo que van a dar una información más interesante. Esta siguiente está generada con el socnetv, aplicando una de las ordenaciones en circulo por centralidad (en este caso, creo, "in degree centrality"):

Usando el comando nop bp.file | twopi -Tpng -o bptwopi.png, de graphviz:

La imagen que más me gusta es esta, que da alguna información de la organización, pero acercándose uno puede ver detalles (usando nop bp.file | fdp -Tpng -o bpfdp.png)... Lo malo es que subiéndola a flickr se baja tanto la resolución como la calidad. Se admiten sugerencias para subir las imágenes a un sitio donde las dejen poner a mucha resolución...Actualización: Gracias a resete-e y su cuenta de flickr pro hay imágenes de alta resolución. Muchas gracias ;)
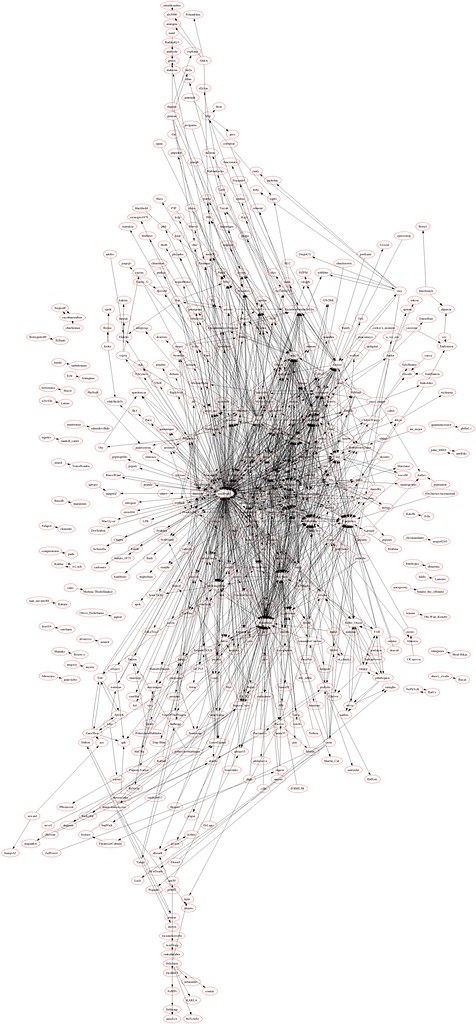
La red social de menéame
Mientras iba haciendo el primer programa, se me ocurrió que casi por el mismo precio podría tener un segundo programa que obtuviese los datos de menéame. Solo apuntar que en este caso la red está aún más enmarañada porque hay más actores y más relaciones...
Las imágenes análogas a las anteriores serían:
(Nota: La última imagen parece en negro, pero si se pincha sobre ella sale a resolución completa...)


 Los datos
Los datos No tenía donde poner los ficheros de datos, pero
Eduardo de http://hombrelobo.com/ me cedió amablemente espacio, así que todos los interesados en los datos en bruto pueden jugar con ellos y con
graphviz,
SocNetV y con lo que quieran. Traté de embeber los svg en HTML, pero creo que no merece la pena porque son muy grandes y firefox (al menos) se queda un poco tonto. Mejor bajárselos y verlos con algún visor... Bueno, los enlaces:
Que los disfruten ;)
"Análisis"
Se ve que hay islitas, cosa que me ha sorprendido, por aquello de los seis grados de separación, pero también lo comentaba Ugarte en su entrada. Pensándolo un poco más detenidamente, tanto en este caso como en el de los enlaces feevy son casi todas relaciones fuertes en el sentido en el que se comenta en un mar de flores. No todas las relaciones débiles entre usuarios (yo leo poco a tal, yo conozco a cual, pero no le sigo) no salen en este esquema, es seguro que en ese caso todos estarían conectados... No obstante, en el caso de las gráficas de las dos comunidades, las islas son menores que en feevy, la red está más clusterizada... (este razonamiento hay que tomarlo con precaución: yo soy sólo un aficionado ;))
Más redes
Se me pasó por la cabeza un proyecto más ambicioso en en que se definiesen parámetros de búsqueda (expresiones regulares y alguna otra cosa...) pero me resultó demasiado grande para el poco uso que le iba a dar. Si alguien tiene ganas, se puede modificar muy fácilmente para sacar la red de slashdot (casi trivial) o de digg... ¿twitter? (por cierto, que alguien sacó el gráfico de los usuarios holandeses de twitter, también vía de Ugarte)
Erlang
En otro orden de cosas... lo he programado en Erlang y ha sido una gratísima experiencia. Hay quien dice que la iteración es humana, la recursión es divina, pero Erlang con su tail recursion (recusión terminal) te la facilita o más bien te la hace obligatoria para recorrer los conjuntos de datos. Pero tanto el uso de esa recursión, el manejo de listas y tuplas como la sintaxis me ha resultado muy muy natural. El hecho de que cada "sentencia" sea separada por comas, el final un punto, las flechas... todo muy intuitivo, un poco como escribir un texto, salvando las distancias ;)
Otro punto fuerte de el lenguaje es el tratamiento de la concurrencia, que es muy sencillo teniendo en cuenta una serie de premisas que ya comentó Joe Armstrong en su entrevista en Thinking parallel. Erlang no usa threads nativos sino que tiene sus propios "procesos ligeros" con lo que logra una gran escalabilidad en cuanto a número de procesos disponibles.
En este ejemplo no se observa muy bien, porque no creo que el programa lo requiriese, pero el lector atento del código podría añadirle una cierta concurrencia para hacer peticiones en paralelo, pero en este caso no es muy útil...
Aquí voy a pegar el código que he usado tal cual, con la advertencia que no es un código muy probado y tal y cual, etc, etc :)
(por cierto y a modo de recordatorio, el comando que he usado para generar el código HTML con resaltado de sintaxis es enscript --highlight=erlang --color --language=html --output=soc_graph.html soc_graph.erl)
Blogger se comió los tabuladores, los he sustituido por espacios...
El programa de barrapunto:
-module(soc_graph).
-export([do_it/0]).
-export([get_friends/1]).
-export([get_users/1]).
do_it() ->
init_file(),
get_users({self(),1}),
end_file().
%get_users gets user list
get_users({Pid,Step}) -> get_users(0,{Pid,Step}).
get_users(Pan,{Pid,Step}) ->
URL=io_lib:format("http://barrapunto.com/search.pl?threshold=-1&op=users&sort=1i&start=~.10B",[Pan]),
{ ok, {Status, Headers, Body }} = http:request(URL),
{match, Matches}=regexp:matches(Body,"barrapunto.com/~.*/journal"),
Lst_new = [string:substr(Body,Start+16 ,Length-16-8 ) || {Start,Length} <- Matches],
case Lst_new of
[] -> get_users_done;
%_ -> spawn(soc_graph,get_friends,[{Pid,Lst_new}]),
_ -> get_friends({Pid,Lst_new}),
get_users(Step+Pan,{Pid,Step})
end.
%get_friends gets user id and get friend list
%Pid is unused (refactoring?)
get_friends({Pid,[H|T]}) ->
URL=io_lib:format("http://barrapunto.com/~~~s/friends",[H]),
io:format("~s~n",[H]),
{ ok, {Status, Headers, Body }} = http:request(URL),
Reg_exp="barrapunto.com/~.*/friends",
{match, Matches}=regexp:matches(Body,"barrapunto.com/~.*/friends"),
Frnd_new = [string:substr(Body,Start+16 ,Length-16-8 ) || {Start,Length} <- Matches],
New_user=replace_forb_chars(H),
Frnd_flt=lists:filter(noself(New_user),Frnd_new),
to_file([{H,Frnd_flt}]),
get_friends({Pid,T});
get_friends({Pid,[]}) -> ok_friends.
noself(H) ->
fun(S) ->
case regexp:match(S,H) of
{match,_,_} -> false;
nomatch -> true;
{error,_} -> true
end
end.
%replace_forb_char replaces special (regexp) characters in user name
replace_forb_chars(S) ->
replace_forb_chars(S,".$()*+").
replace_forb_chars(S,[RH|RT]) ->
Regexp="["++[RH]++"]",
{ok,Newstr,_}=regexp:gsub(S,Regexp,Regexp),
replace_forb_chars(Newstr,RT);
replace_forb_chars(S,[]) ->
S.
%to_file writes friends into DOT file
to_file(Frnd) ->
%this line violates DRY (Refactor?)
{ok,F}=file:open("bp.file",[write]),
to_file(F,Frnd).
to_file(F,[{User,Frnds}|T]) ->
%TODO: Format of map/frineds
Out_Frnd= fun(Frnd)-> io:format(F,"\"~s\" -> \"~s\"~n",[User,Frnd]) end,
lists:map(Out_Frnd,Frnds),
to_file(F,T);
to_file(F,[]) ->
file:close(F),
ok_to_file.
%init_file initializes the DOT file
init_file() ->
%this line violates DRY (Refactor?)
{ok,F}=file:open("mnm.file",[write]),
io:format(F,"digraph mydot {~nnode [color=red, shape=ellipse];~n",[]),
file:close(F).
%end_file inserts the coda in the DOT file
end_file() ->
%this line violates DRY (Refactor?)
{ok,F}=file:open("mnm.file",[append]),
io:format(F,"[weight=1, color=black];~n}~n",[]),
file:close(F).
La modificación para menéame:
-module(soc_graph).
-export([do_it/0]).
-export([get_friends/1]).
-export([get_users/1]).
do_it() ->
init_file(),
get_users({self(),1}),
end_file().
%get_users gets user list
get_users({Pid,Step}) -> get_users(1,{Pid,Step}).
get_users(Pan,{Pid,Step}) ->
URL=io_lib:format("http://meneame.net/topusers.php?sortby=0&page=~.10B",[Pan]),
{ ok, {Status, Headers, Body }} = http:request(URL),
{match, Matches}=regexp:matches(Body,"/user/[^\"]*"),
Lst_new = [string:substr(Body,Start+6 ,Length-6) || {Start,Length} <- Matches],
case Lst_new of
[] -> get_users_done;
%_ -> spawn(soc_graph,get_friends,[{Pid,Lst_new}]),
_ -> get_friends({Pid,Lst_new}),
timer:sleep(1000),
get_users(Step+Pan,{Pid,Step})
end.
%get_friends gets user id and get friend list
%Pid is unused (refactoring?)
get_friends({Pid,[H|T]}) ->
URL=io_lib:format("http://meneame.net/user/~s/friends",[H]),
io:format("~s~n",[H]),
Reg_exp="friends_of=[^\"]*",
{ ok, {Status, Headers, Body }} = http:request(URL),
{match, Start, Length}=regexp:match(Body,Reg_exp),
User_Id = string:substr(Body,Start+11 ,Length-11 ),
Frnd_new=get_friends_page(1,User_Id,[]),
New_user=replace_forb_chars(H),
Frnd_flt=lists:filter(noself(New_user),Frnd_new),
to_file([{H,Frnd_flt}]),
get_friends({Pid,T});
get_friends({Pid,[]}) -> ok_friends.
%get_friends_page gets friend list
%Pid is unused (refactoring?)
get_friends_page(Page,User_Id,Frnd) ->
Reg_exp2="/user/[^\"]*",
URL2=io_lib:format("http://meneame.net/backend/get_friends_bars.php?id=~s&p=~.10B&type=from",[User_Id,Page]),
{ ok, {Status2, Headers2, Body2 }} = http:request(URL2),
{match, Matches}=regexp:matches(Body2,Reg_exp2),
Frnd_new = [string:substr(Body2,Start2+6 ,Length2-6) || {Start2,Length2} <- Matches],
case Frnd_new of
[] -> Frnd;
_ -> get_friends_page(Page + 1,User_Id,lists:append(Frnd,Frnd_new))
end.
noself(H) ->
fun(S) ->
case regexp:match(S,H) of
{match,_,_} -> false;
nomatch -> true;
{error,_} -> true
end
end.
%replace_forb_char replaces special (regexp) characters in user name
replace_forb_chars(S) ->
replace_forb_chars(S,".$()*+").
replace_forb_chars(S,[RH|RT]) ->
Regexp="["++[RH]++"]",
{ok,Newstr,_}=regexp:gsub(S,Regexp,Regexp),
replace_forb_chars(Newstr,RT);
replace_forb_chars(S,[]) ->
S.
%to_file writes friends into DOT file
to_file(Frnd) ->
%this line violates DRY (Refactor?)
{ok,F}=file:open("mnm.file",[append]),
to_file(F,Frnd).
to_file(F,[{User,Frnds}|T]) ->
%TODO: Format of map/frineds
Out_Frnd= fun(Frnd)-> io:format(F,"\"~s\" -> \"~s\"~n",[User,Frnd]) end,
lists:map(Out_Frnd,Frnds),
to_file(F,T);
to_file(F,[]) ->
file:close(F),
ok_to_file.
%init_file initializes the DOT file
init_file() ->
%this line violates DRY (Refactor?)
{ok,F}=file:open("mnm.file",[write]),
io:format(F,"digraph mydot {~nnode [color=red, shape=ellipse];~n",[]),
file:close(F).
%end_file inserts the coda in the DOT file
end_file() ->
%this line violates DRY (Refactor?)
{ok,F}=file:open("mnm.file",[append]),
io:format(F,"[weight=1, color=black];~n}~n",[]),
file:close(F).
Referencias sobre Erlang






{kind=link}
{kind=link}